SceneScape: Text-Driven Consistent Scene Generation
Supplementary Material
- Our Results (Section 4 and Figure 4)
- Ablations (Section 4.2 and Figure 5)
- Comparisons (Section 4.3 and Figure 6)
- Meshes visualization (Section 3.1)
Please wait for a few seconds for the videos in the page to load
Our Results
Sample results, part of which are shown in Fig.4 in the paper.
POV, cave, pools, water, dark cavern, inside a cave, beautiful scenery, best quality, indoor scene |
POV, haunted house, dark, wooden door, spider webs, skeletons, indoor scene |
walkthrough, inside a medieval forge, metal, fire, beautiful photo, masterpiece, indoor scene |
|---|---|---|
|
Our result
|
Our result
|
Our result
|
| | ||
walkthrough, a medieval dungeon with damp, stone corridors and flickering torches lining the walls, beautiful photo, masterpiece, indoor scene |
A grand, marble staircase spirals up to a vaulted ceiling in a grand entrance hall of a palace |
inside a castle made of ice, beautiful photo, masterpiece |
|
Our result
|
Our result
|
Our result
|
| | ||
walkthrough, an opulent hotel with long, carpeted hallways, beautiful photo, masterpiece, indoor scene |
walkthrough, spaceship interiors, corridors,amazing quality, masterpiece, beautiful scenery, best quality, indoor scene |
A dimly lit library, with rows upon rows of leather-bound books and dark wooden shelves |
|
Our result
|
Our result
|
Our result
|
| | ||
walkthrough, inside a medieval castle, metal, beautiful photo, masterpiece, indoor scene |
walkthrough, a medieval dungeon with damp, stone corridors and flickering torches lining the walls, beautiful photo, masterpiece, indoor scene |
POV, haunted house, dark, wooden door, spider webs, skeletons, indoor scene |
|
Our result
|
Our result
|
Our result
|
| | ||
POV, cave, pools, water, dark cavern, inside a cave, beautiful scenery, best quality, indoor scene |
walkthrough, an opulent hotel with long, carpeted hallways, beautiful photo, masterpiece, indoor scene |
walkthrough, underground bunker with narrow, dimly lit corridors and reinforced metal doors, beautiful photo, masterpiece, indoor scene |
|
Our result
|
Our result
|
Our result
|
| | ||
A dimly lit library, with rows upon rows of leather-bound books and dark wooden shelves |
inside a castle made of ice, beautiful photo, masterpiece |
walkthrough, spaceship interiors, corridors,amazing quality, masterpiece, beautiful scenery, best quality, indoor scene |
|
Our result
|
Our result
|
Our result
|
| | ||
walkthrough, abandoned hospital with empty, sterile corridors, fluorescent lights, cracked linoleum floors, best quality, eerie atmosphere. |
walkthrough, inside a medieval castle, metal, beautiful photo, masterpiece, indoor scene |
Simple museum, pictures, paintings, artistic, best quality, dimly lit |
|
Our result
|
Our result
|
Our result
|
| | ||
A grand, marble staircase spirals up to a vaulted ceiling in a grand entrance hall of a palace |
indoor scene, interior, candy house, fantasy, beautiful, masterpiece, best quality |
|
|
Our result
|
Our result
|
|
| |
Ablations
We ablate the key components in our framework: (i) depth finetuning, (ii) decoder finetuning, (iii) mesh representation. We also show results of a naive warp-inpaint baseline. Without each of our components, the produced videos suffer from visual artifacts (e.g blur without mesh representation, stretches without depth finetuning, high-frequency flickering without decoder finetuning). For discussion and numerical evaluations, please see Sec. 4.1 and 4.2 in the paper.
| POV, cave, pools, water, dark cavern, inside a cave, beautiful scenery, best quality, indoor scene |
|---|
|
|
|
Our result
w/o depth fine-tuning
w/o decoder fine-tuning
w/o mesh representation
naive warp-inpaint
|
| |
| A dimly lit library, with rows upon rows of leather-bound books and dark wooden shelves |
|
|
|
Our result
w/o depth fine-tuning
w/o decoder fine-tuning
w/o mesh representation
naive warp-inpaint
|
| |
| inside a castle made of ice, beautiful photo, masterpiece |
|
|
|
Our result
w/o depth fine-tuning
w/o decoder fine-tuning
w/o mesh representation
naive warp-inpaint
|
| |
| walkthrough, an opulent hotel with long, carpeted hallways, beautiful photo, masterpiece, indoor scene |
|
|
|
Our result
w/o depth fine-tuning
w/o decoder fine-tuning
w/o mesh representation
naive warp-inpaint
|
| |
| POV, haunted house, dark, wooden door, spider webs, skeletons, indoor scene |
|
|
|
Our result
w/o depth fine-tuning
w/o decoder fine-tuning
w/o mesh representation
naive warp-inpaint
|
| |
| |
Splatting
We compare our method to Splatting baseline with horizontal camera translations. This additionally demonstrates the need of a unified 3D representation:
| | |
POV, beautiful room, wardrobe, bed, table, side view |
a wall in a museum with paintings, beautiful photo, masterpiece |
|---|---|
|
Our result
"Splatting"
|
Our result
"Splatting"
|
Comparisons
The following videos include comparison results to the following baselines (Sec. 4.3 in the paper):
- VideoFusion [2]: A text-to-video diffusion model2, which takes as input a text prompt and produces a 16-frame long video at 256 × 256 resolution.
- GEN-1 [1]: A text-driven video-to-video translation model, where the translation is conditioned on depth maps estimated from an input source video. Note that in our setting the scene geometry is unknown and is constructed together with the video, whereas GEN-1 takes the scene geometry as input, thus tackling a simpler task.
In addition, we include a qualitative comparison to StableDreamFusion [4], an open-source implementation of DreamFusion [3], a text-to-3D method.
Sample comparisons to GEN-1
indoor scene, interior, candy house, fantasy, beautiful, masterpiece, best quality |
POV, haunted house, dark, wooden door, spider webs, skeletons, indoor scene |
walkthrough, an opulent hotel with long, carpeted hallways, beautiful photo, masterpiece, indoor scene |
|---|---|---|
|
Our result
GEN-1 result
|
Our result
GEN-1 result
|
Our result
GEN-1 result
|
| | ||
A dimly lit library, with rows upon rows of leather-bound books and dark wooden shelves. |
walkthrough, inside a medieval castle, metal, beautiful photo, masterpiece, indoor scene |
|
|
Our result
GEN-1 result
|
Our result
GEN-1 result
|
|
| |
Note that GEN-1 videos appear to be "lagging" since GEN-1 occasionaly produces near-duplicate frames.
We demonstrate the resulting point cloud, produced by COLMAP reconstruction, on our method and on GEN-1, given the camera path. We also visualize the cameras by boxes with alternating colors.
| | |

Our result
|
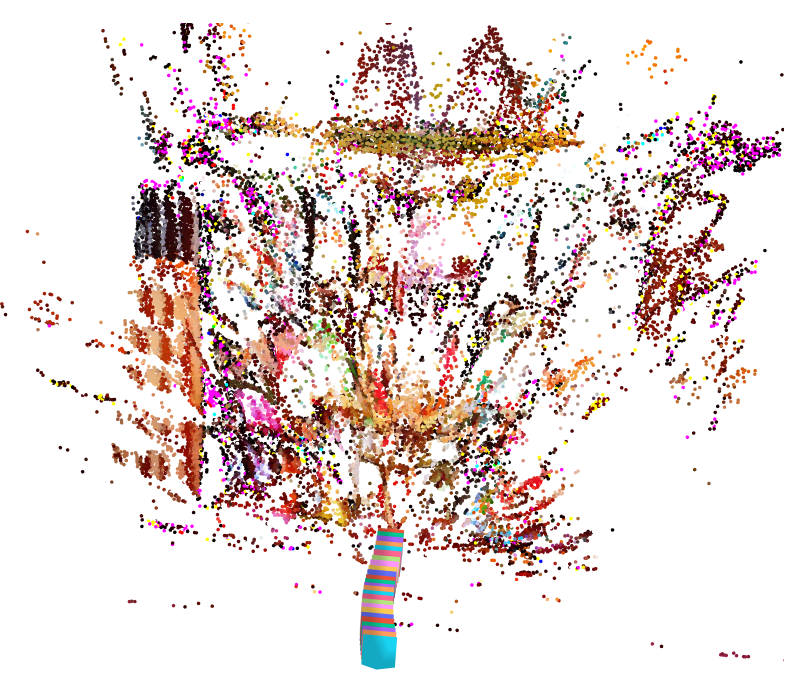
GEN-1 result
|
| |
Sample comparisons to VideoFusion
Note that VideoFusion produces shorter videos and there is no explicit control over the camera motion.
walkthrough, inside a medieval castle, metal, beautiful photo, masterpiece, indoor scene |
walkthrough, inside a medieval forge, metal, fire, beautiful photo, masterpiece, indoor scene |
inside a castle made of ice, beautiful photo, masterpiece |
|---|---|---|
|
Our result
VideoFusion result
|
Our result
VideoFusion result
|
Our result
VideoFusion result
|
| | ||
walkthrough, spaceship interiors, corridors,amazing quality, masterpiece, beautiful scenery, best quality, indoor scene |
Simple museum, pictures, paintings, artistic, best quality, dimly lit |
POV, cave, pools, water, dark cavern, inside a cave, beautiful scenery, best quality, indoor scene |
|
Our result
VideoFusion result
|
Our result
VideoFusion result
|
Our result
VideoFusion result
|
| | ||
indoor scene, interior, candy house, fantasy, beautiful, masterpiece, best quality |
A dimly lit library, with rows upon rows of leather-bound books and dark wooden shelves. |
POV, haunted house, dark, wooden door, spider webs, skeletons, indoor scene |
|
Our result
VideoFusion result
|
Our result
VideoFusion result
|
Our result
VideoFusion result
|
| |
Comparison to StableDreamFusion
We compare our method to StableDreamFusion, an open-source text-to-3D model that creates an implicit representation of a scene from our camera trajectory and a prompt. The generated scenes contain blur and unrealistic artifacts which demonstrates the failure of current 3D methods to create such videos - to achieve good quality, NERF requires multiple viewpoints of the scene from different angles.
| a DSLR photo of the inside of a hotel | a DSLR photo of the inside of a haunted house | a DSLR photo of the inside of a medieval castle | a DSLR photo of the inside of a candy house | a DSLR photo of the inside of a library | a DSLR photo of the inside of a cave |
|---|---|---|---|---|---|
|
|
|
|
|
|
|
| |
Meshes visualization
We demonstrate the resulting meshes, produced by our method and post processed with Poisson surface reconstruction.
| | |
POV, cave, pools, water, dark cavern, inside a cave, beautiful scenery, best quality, indoor scene |
indoor scene, interior, candy house, fantasy, beautiful, masterpiece, best quality |
|---|---|
|
|
|
| |
[1] Patrick Esser, Johnathan Chiu, Parmida Atighehchian, Jonathan Granskog, and Anastasis Germanidis. Structure and content-guided video synthesis with diffusion models. arXiv preprint arXiv:2302.03011, 2023.
[2] Zhengxiong Luo, Dayou Chen, Yingya Zhang, Yan Huang, LiangWang, Yujun Shen, Deli Zhao, Jingren Zhou, and Tieniu Tan. Videofusion: Decomposed diffusion models for high-quality video generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023.
[3] Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion. arXiv, 2022.
[4] Jiaxiang Tang. 2022. Stable-dreamfusion: Text-to-3D with Stable-diffusion https://github.com/ashawkey/stable-dreamfusion.