SceneScape: Text-Driven Consistent Scene Generation
| 1 Weizmann Institute of Science |
| 2 NVIDIA Research |
| | Paper | Supplementary Material | Code |
Abstract
We present a method for text-driven perpetual view generation -- synthesizing long-term videos of various scenes solely from an input text prompt describing the scene and camera poses. We introduce a novel framework that generates such videos in an online fashion by combining the generative power of a pre-trained text-to-image model with the geometric priors learned by a pre-trained monocular depth prediction model. To tackle the pivotal challenge of achieving 3D consistency, i.e., synthesizing videos that depict geometrically-plausible scenes, we deploy an online test-time training to encourage the predicted depth map of the current frame to be geometrically consistent with the synthesized scene. The depth maps are used to construct a unified mesh representation of the scene, which is progressively constructed along the video generation process. In contrast to previous works, which are applicable only to limited domains, our method generates diverse scenes, such as walkthroughs in spaceships, caves, or ice castles.
How It Works
We represent the generated scene with a unified mesh $\mathcal{M}$, which is constructed in an online fashion. Given a camera at $\boldsymbol{C_{t+1}}$, at each synthesis step, a new frame is generated by projecting $\mathcal{M}_t$ into $\boldsymbol{C}_{t+1}$, and synthesizing the newly revealed content by using a pre-trained text-to-image diffusion model. To estimate the geometry of the new synthesized content, we leverage a pre-trained depth prediction model; to ensure the predicted depth is consistent with the existing scene $\mathcal{M}_t$, we deploy a test-time training, encouraging the predicted depth by the model to match the projected depth from $\mathcal{M}_t$. We then update our mesh representation to form $\mathcal{M}_{t+1}$ which includes the new scene content.
A visualization of the resulting meshes, produced by our method and post processed with Poisson surface reconstruction.
| | |
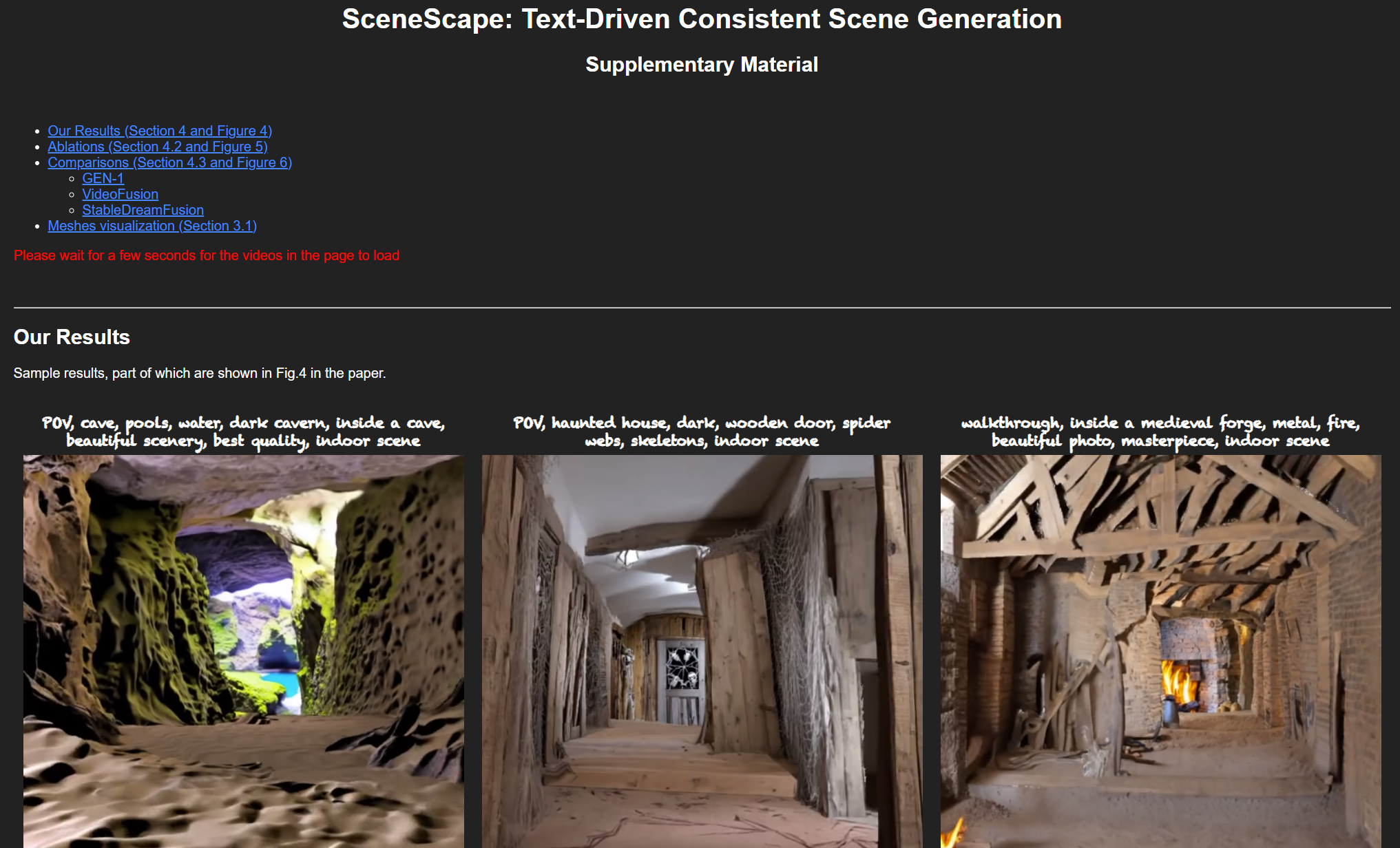
POV, cave, pools, water, dark cavern, inside a cave, beautiful scenery, best quality, indoor scene |
indoor scene, interior, candy house, fantasy, beautiful, masterpiece, best quality |
|---|---|
Depth Model Finetuning
Monocular depth predictions tend to be inconsistent, even across nearby video frames. That is, there is no guarantee the predicted depth of the frame would be well aligned with the current scene geometry. We mitigate this problem by taking a test-time training approach to finetune the depth prediction model to be consistent as possible with the current scene geometry.
walkthrough, an opulent hotel with long, carpeted hallways, beautiful photo, masterpiece, indoor scene
inside a castle made of ice, beautiful photo, masterpiece
POV, haunted house, dark, wooden door, spider webs, skeletons, indoor scene
Here we demonstrate the effect of the depth model finetuning. As can bee seen, without it, the MiDaS predictions are inconsistent across time.
Paper
 |
SceneScape: Text-Driven Consistent Scene Generation
|
Supplementary Material
 |
Bibtex
Acknowledgments
We thank Shai Bagon for his insightful comments. We thank Narek Tumanyan for his help with the website.